"The introduction of Multi-Token Attention allows transformers to simultaneously focus on groups of tokens, overcoming limitations of traditional single-token attention mechanisms."
"Multi-token attention extends the capability of standard attention mechanisms by enhancing the model's ability to capture interdependencies amongst multiple tokens in a sequence."
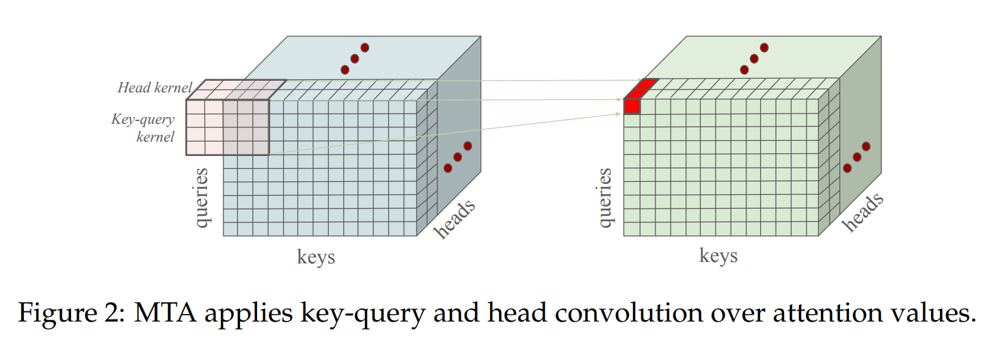
Transformers have changed natural language processing with traditional attention focusing on single tokens. However, the new Multi-Token Attention (MTA) mechanism enables models to assess and focus on clusters of tokens simultaneously, improving contextual understanding. Standard attention operates on individual tokensâ relevance, utilizing dot products for scoring. MTA expands this functionality, allowing for a more nuanced analysis of sequences, essential for tasks requiring comprehension of relationships among multiple tokens. This innovation brings both advantages in model capability and challenges in implementation, particularly affecting language models and multi-modal frameworks.
#natural-language-processing #transformers #attention-mechanisms #multi-token-attention #machine-learning
Read at Medium
Unable to calculate read time
Collection
[
|
...
]