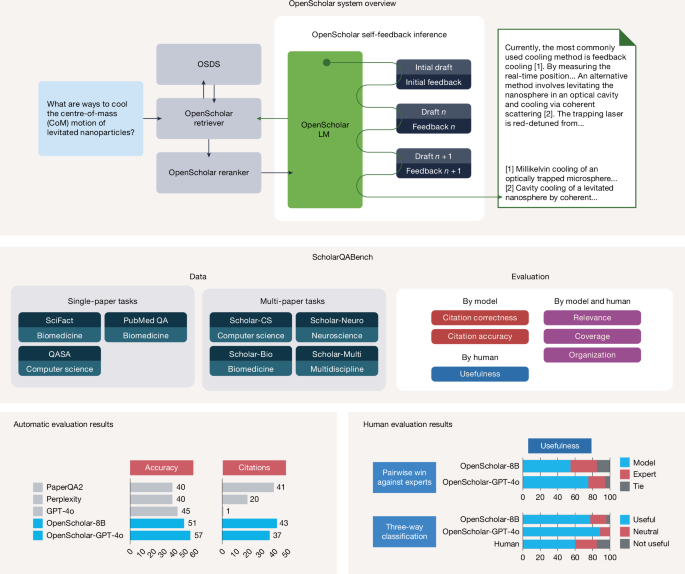
"Synthesizing knowledge from the scientific literature is essential for discovering new directions, refining methodologies and supporting evidence-based decisions, yet the rapid growth of publications makes it increasingly difficult for researchers to stay informed. Effective synthesis requires precise retrieval, accurate attribution and access to up-to-date literature. LLMs can assist but suffer from hallucinations2,3, outdated pre-training data4 and limited attribution. In our experiments, GPT-4o fabricated citations in 78-90% of cases when asked to cite recent literature across fields such as computer science and biomedicine."
"To address the challenges of accurate, comprehensive and transparent scientific literature synthesis, we introduce OpenScholar (Fig. 1, top), to our knowledge the first fully open, retrieval-augmented LM specifically designed for scientific research tasks. OpenScholar integrates a domain-specialized data store (OpenScholar DataStore, OSDS), adaptive retrieval modules and a new self-feedback-guided generation mechanism that enables iterative refinement of long-form outputs. OSDS is a fully open, up-to-date corpus of 45 million scientific papers and 236 million passage embeddings, offering a reproducible foundation for training and inference."
Rapid growth of scientific publications makes it difficult for researchers to stay informed, and effective synthesis requires precise retrieval, accurate attribution, and up-to-date literature. Large language models can assist but suffer from hallucinations, outdated pre-training data, and limited attribution, with GPT-4o fabricating citations in 78–90% of cases when asked to cite recent literature. Retrieval-augmented models mitigate some issues by incorporating external knowledge at inference, but many use black-box APIs, general-purpose LMs, and lack open, domain-specialized retrieval data stores. OpenScholar is an open, retrieval-augmented system designed for scientific research that integrates OSDS, trained retrievers and rerankers, adaptive retrieval modules, and a self-feedback-guided generation mechanism for iterative refinement. OSDS contains 45 million papers and 236 million passage embeddings, providing an up-to-date, reproducible foundation for training, retrieval, citation generation, and long-form literature synthesis.
#retrieval-augmented-models #scientific-literature-synthesis #openscholar-datastore #llm-hallucinations
Read at Nature
Unable to calculate read time
Collection
[
|
...
]