#differential-privacy
#differential-privacy
[ follow ]


Artificial intelligence
fromTechzine Global
7 months agoGoogle launches VaultGemma: privacy AI without compromising performance
VaultGemma is a 1B-parameter differentially private language model that preserves performance while preventing memorization or leakage of sensitive data and will be open source.
Artificial intelligence
fromodsc.medium.com
8 months agoTokenizing Text for LLMs, an AI Agent Dictionary, Optimizing Agentic Workflows, and AI for Robotics at ODSC West
AI for robotics integrates foundation models, autonomous navigation, manipulation, agentic workflows, tokenization, metadata protocols, differential-privacy synthetic data, and hands-on training including a robotics hackathon prize.
Privacy technologies
fromHackernoon
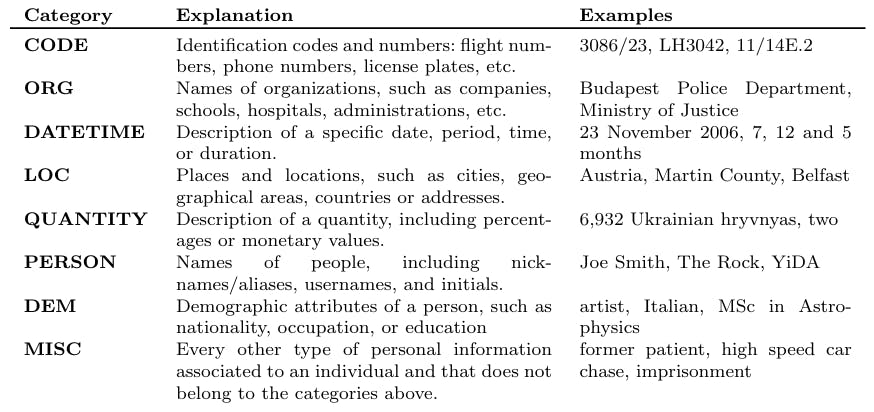
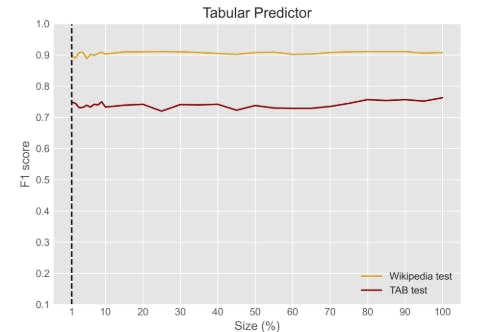
2 years agoLLM Probabilities, Training Size, and Perturbation Thresholds in Entity Recognition | HackerNoon
The article explores the intersection of natural language processing and privacy, emphasizing Differential Privacy as a method to protect data.
The research identifies key indicators for evaluating privacy risks in NLP applications.
[ Load more ]