"In traditional systems, side effects lead to increased complexity, debugging challenges, and unpredictable behavior. CocoIndex adopts a pure data flow programming approach, ensuring reliability."
"CocoIndex embraces the Data Flow Programming paradigm, where data transformations are observable, traceable, and immutable, which simplifies complex pipelines in areas like knowledge extraction."
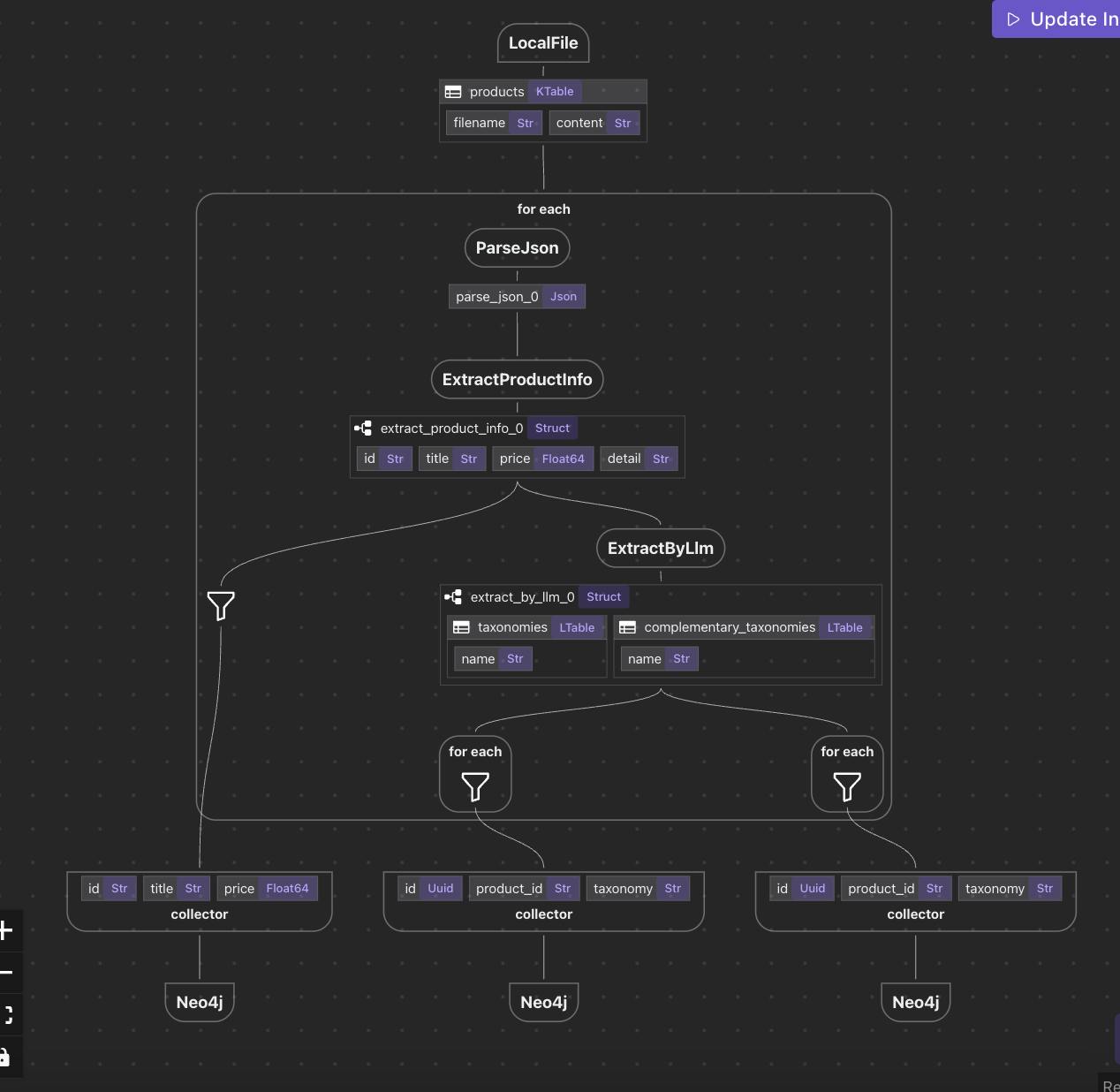
"Data Flow Programming is a declarative model where data flows through a graph of transformations, ensuring each transformation is pure without hidden side effects."
"In CocoIndex, data is treated as the primary unit of composition rather than tasks, allowing for clearer data transformations and simpler debugging."
CocoIndex revolutionizes data orchestration by implementing a pure data flow programming model that prioritizes clear, immutable, and traceable data transformations. Unlike traditional frameworks where data handling is often an afterthought, CocoIndex views data as a primary unit of composition. In this paradigm, each data transformation is devoid of hidden side effects or state mutations, significantly reducing complexity and improving reliability. The model is particularly beneficial for applications in knowledge extraction, graph building, and semantic search, resulting in a more intuitive experience for managing complex data pipelines.
Read at Hackernoon
Unable to calculate read time
Collection
[
|
...
]